 한국연구재단 석사과정생연구장려금지원사업 선정
한국연구재단 석사과정생연구장려금지원사업 선정
이번에 한국연구재단에서 지원하는 석사과정생 연구장려금 지원사업에 최종 선정됐습니다! 🎉
제안한 연구 주제는 “차세대 지능형 교통안전시스템을 위한 컴퓨터 비전 기반 도로 위험행동 예측 모델의 개인화 준지도 연합학습 연구”입니다. 많은 지원자들과 경쟁해 선정된 만큼, 앞으로 책임감을 가지고 연구에 임하려고 합니다.
사업은 2024년 9월 1일부터 2025년 8월 31일까지 총 12개월간 진행되며, 총 1,200만원의 연구비가 지원됩니다.
1. 최종 목표
- Vision-traffic context기반 교통위험행동 예측모델 개발
- 대규모 Non-labeled 분산데이터의 효율적 처리를 위한 준지도 연합학습 기법 개발
- 지역, 도로유형 등의 특성을 고려하기 위한 개인화 연합학습 기법 제안
쉽게 말하면, 실제 도로 상황을 잘 이해하기 위해 Vision 기반의 모델을 구축하고, 다양한 지역의 CCTV 데이터를 효율적으로 활용할 수 있도록 개인화/준지도 연합학습 기법을 제안하는 연구입니다.
2. 연구 배경
도로 위에서 발생하는 보행자 사고나 위험 행동은 여전히 큰 사회적 문제입니다. 그런데 지금까지의 교통안전 시스템은 정형화된 규칙에 기반해 작동하거나, 일부 센서 데이터에만 의존하는 경우가 많아 복잡한 실제 도로 환경을 충분히 반영하지 못하는 한계가 있습니다.
특히 도로 곳곳에 설치된 CCTV는 매일 방대한 양의 영상을 수집하고 있지만, 대부분은 레이블이 없고 정제되지 않아 제대로 학습하기 어려운 상황입니다. 게다가 지역마다 도로 구조, 교통량, 보행자 패턴 등이 모두 다르기 때문에 하나의 모델로 모든 지역을 대표하는 모델을 구축하는 것이 매우 어렵습니다.
그래서 저는
- Unlabeled 상태의 영상 데이터도 효과적으로 활용할 수 있는 방법
- 지역이나 도로 유형에 따라 유연하게 동작하는 개인화된 AI 모델
이 두 가지를 동시에 해결할 수 있는 연구를 제안하였습니다.
즉, 실제 도로 상황을 잘 이해하고 다양한 지역의 CCTV 데이터를 효율적으로 활용하기 위한, 준지도 학습 기반의 개인화 연합학습 연구가 꼭 필요하다고 판단했습니다.
3. 연구 내용
연구는 크게 두 가지 목표로 나눠서 진행할 예정입니다.
목표 1: Vision-traffic context 기반 교통위험행동 예측 모델 개발
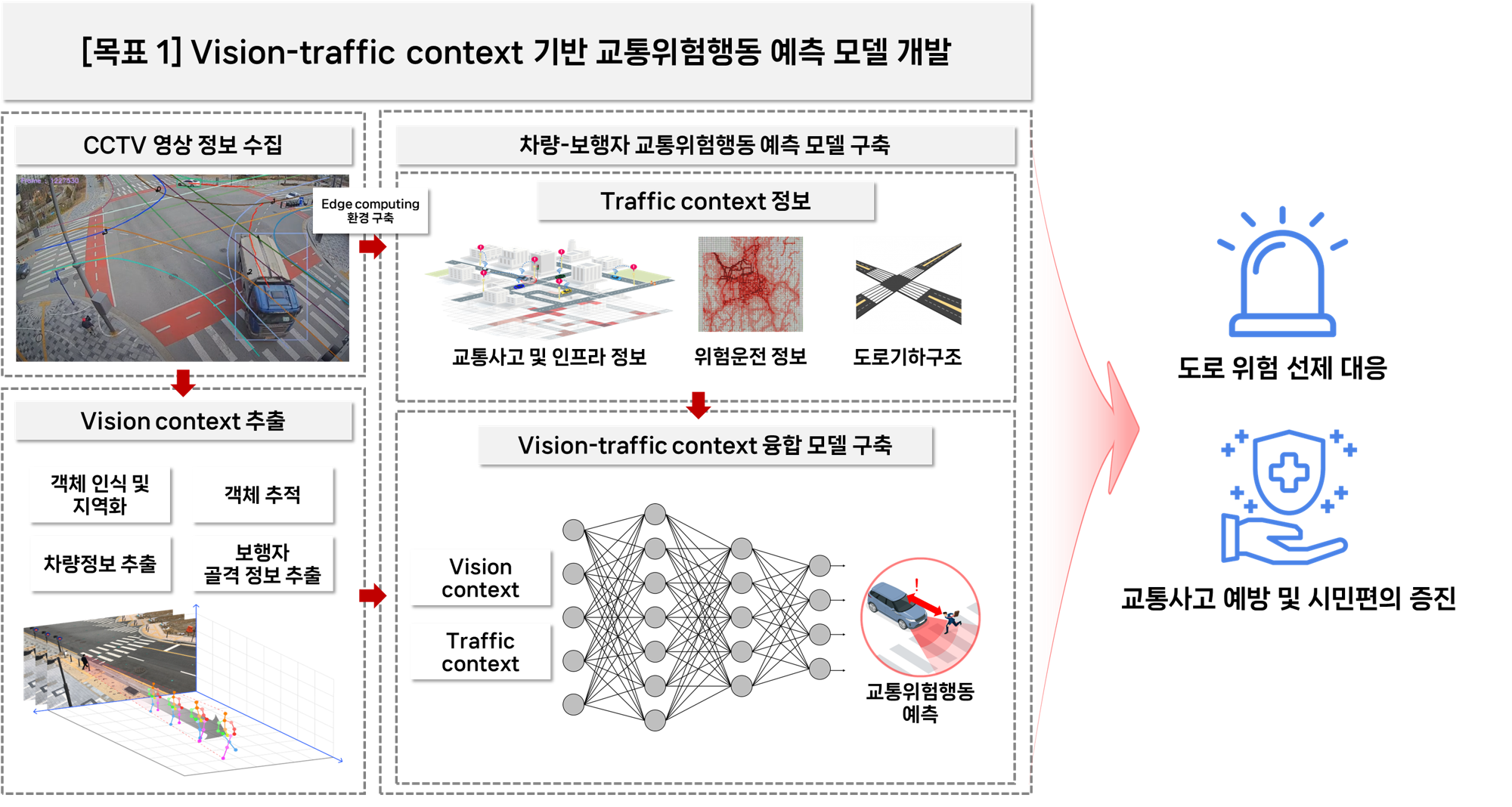
도로 위 다양한 객체(보행자, 차량 등)의 움직임과 주변 도로 환경을 함께 이해할 수 있는 Vision-traffic context 기반 교통위험행동 예측 모델을 만드는 것이 첫 번째 목표입니다. 이를 통해 복잡한 교통 상황 속에서도 위험 행동을 더 정확하게 예측할 수 있도록 합니다.
목표 2: 개인화 준지도 연합학습 모델 개발

두 번째 목표는 다양한 지역에서 수집된 Unlabeled data를 효과적으로 활용하고, 지역별 특성에 맞게 모델이 유연하게 작동할 수 있도록 준지도 학습과 개인화 연합학습 기법을 결합하는 것입니다.
4. 개인적인 다짐
이번 연구장려금 선정은 저의 연구 주제가 실제 사회 문제 해결에 기여할 수 있음을 인정받았다는 점에서 매우 의미가 큽니다.
앞으로의 1년 동안 책임감을 가지고 연구를 수행하고, 현장 적용 가능성이 높은 모델을 만들기 위해 최선을 다하겠습니다.