[Paper Review] A Review of DeepSeek Models' Key Innovative Techniques
arXiv [Paper Link]
Chengen Wang, Murat Kantarcioglu
University of Texas at Dallas, Virginia Tech
14 Mar 2025

1. Introduction
ChatGPT 등장 이후, LLM은 빠르게 발전해 왔으나 LLaMA와 같은 오픈 소스 LLM은 특정 지표에서 경쟁력을 갖춘 결과를 달성했지만, 전반적인 성능은 여전히 독점 모델에 비해 뒤쳐집니다.
DeepSeek-V3와 DeepSeek-R1은 훨씬 적은 Training Resource를 필요로 하면서, 최첨단 GPT 모델과 비슷한 수준의 성능을 달성함
저자들은 이러한 모델의 높은 성능과 효율성의 기반이 되는 기술을 이해하는 것이 중요하다고 강조하며, 다음과 같은 DeepSeek 모델의 핵심 기술을 검토하였습니다:
- Multi-Head Latent Attention (MLA)
- Mixture of Experts (MoE)
- Multi-Token Prediction
- Co-design of Algorithms, Frameworks and Hardware
- Group Relative Policy Optimization (GRPO)
- Post-Training Techniques
또한 DeepSeek의 기술 보고서나 Ablation Study에서 다루지 않은 몇 가지 문제를 확인하고, 잠재적인 연구 기회를 강조하였습니다.
2. The Innovative Techniques
2.1 Multi-Head Latent Attention
KV cache는 Transformer의 Multi-Head Attention (MHA) 블록에서 이전 트큰을 생성할 때 계산한 중간 Key/Value 값을 저장하여, 추론을 가속화하고 반복적인 계산의 필요성을 없애는 데 사용되는 기술입니다.
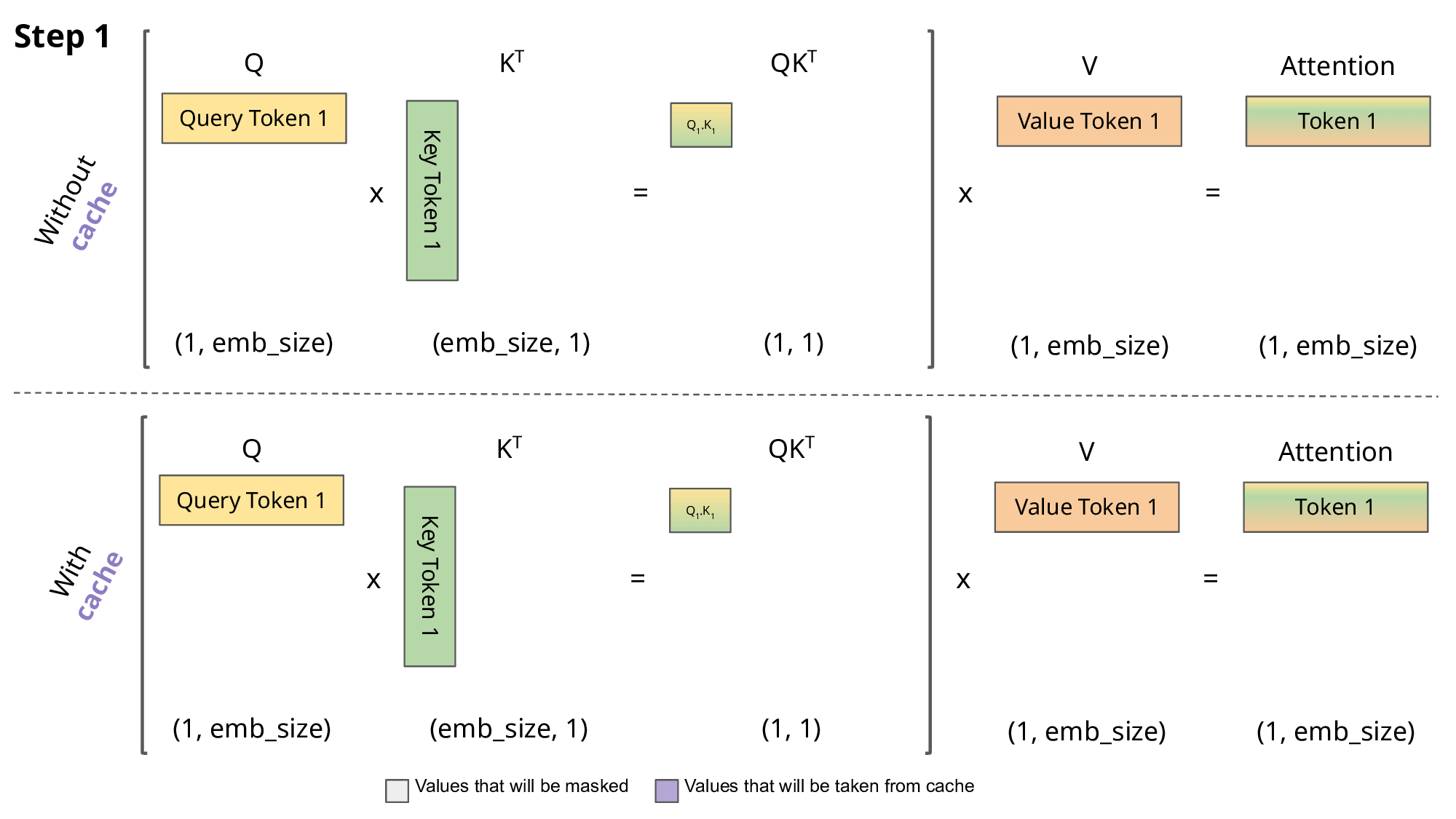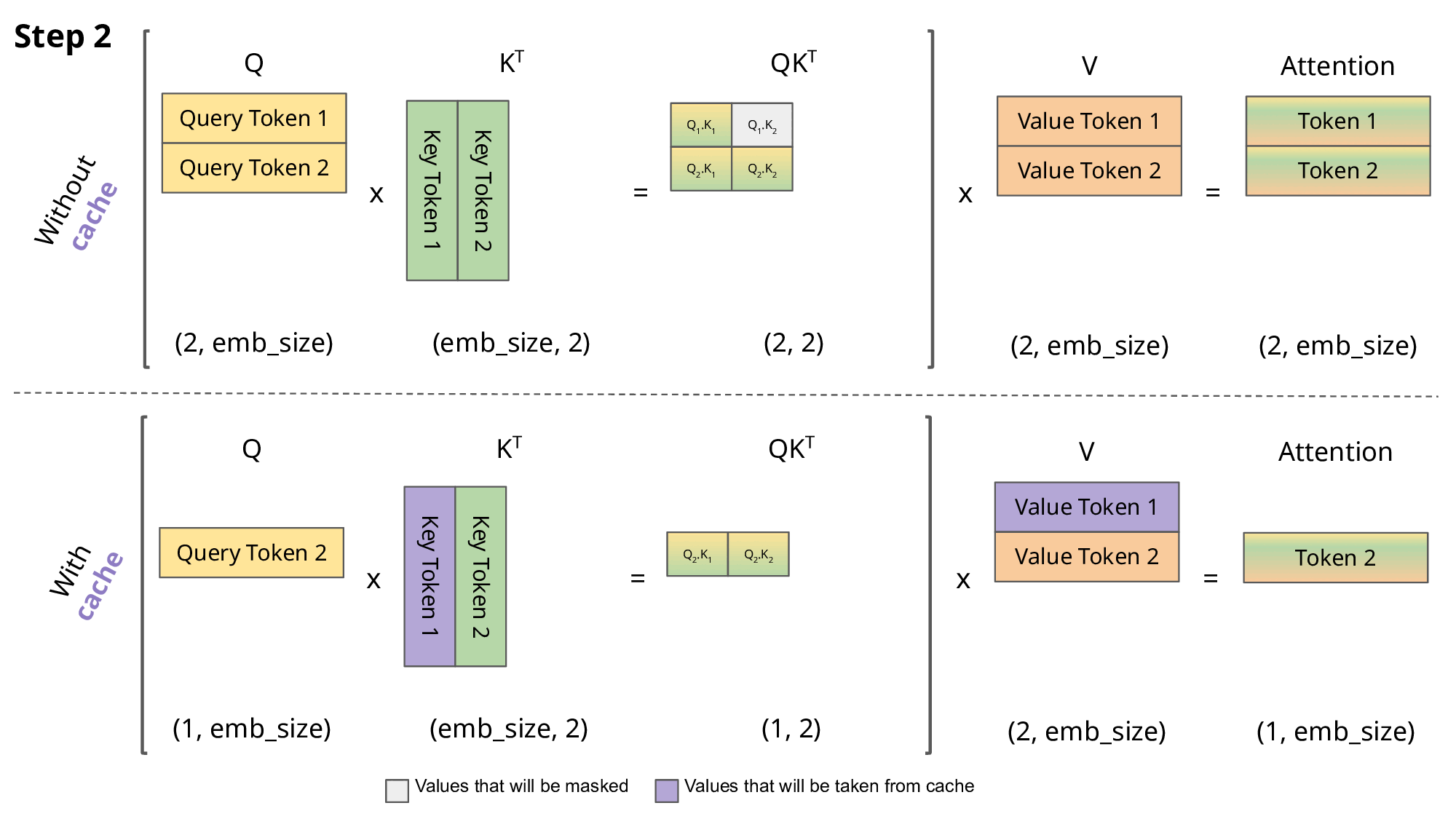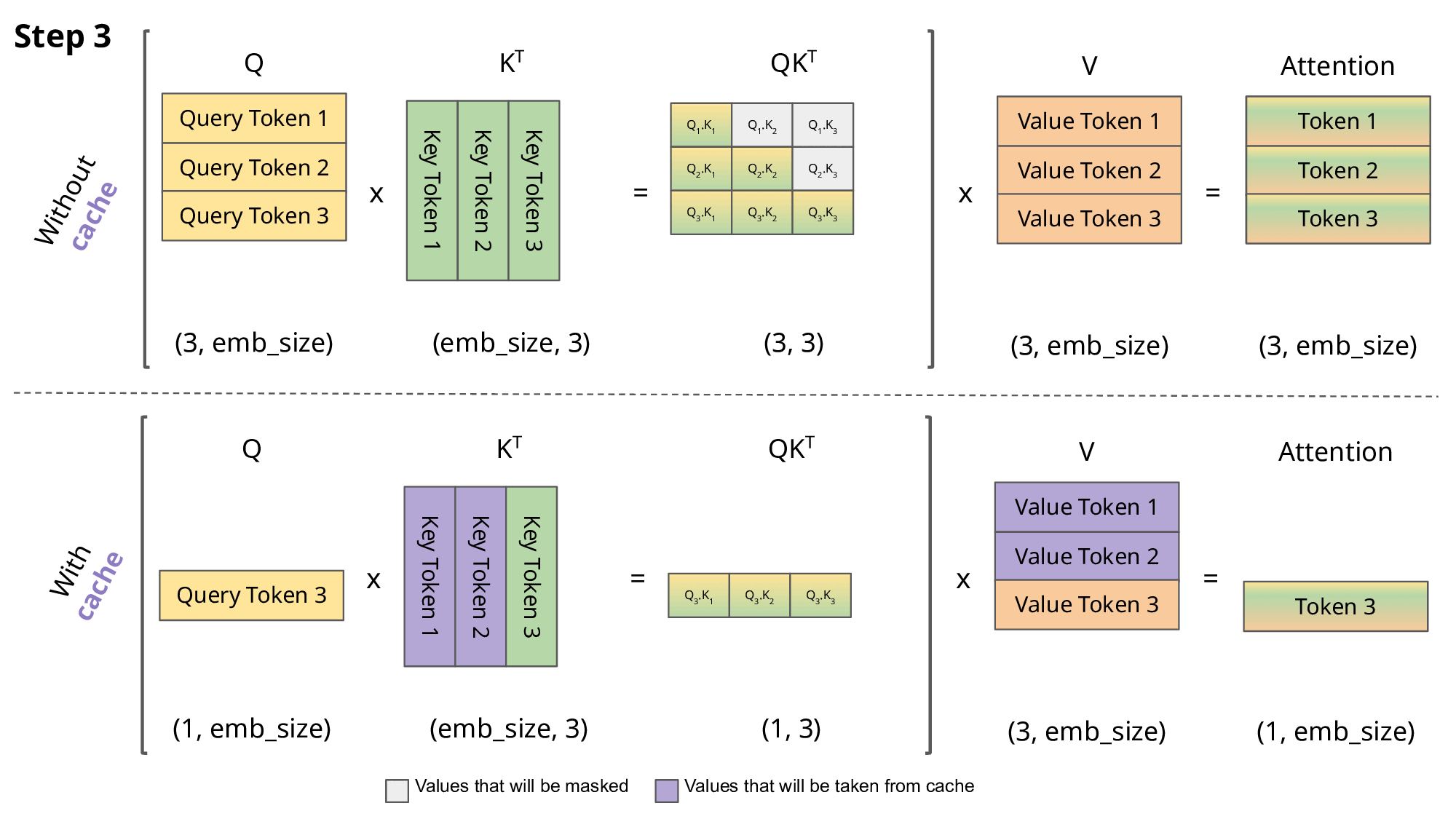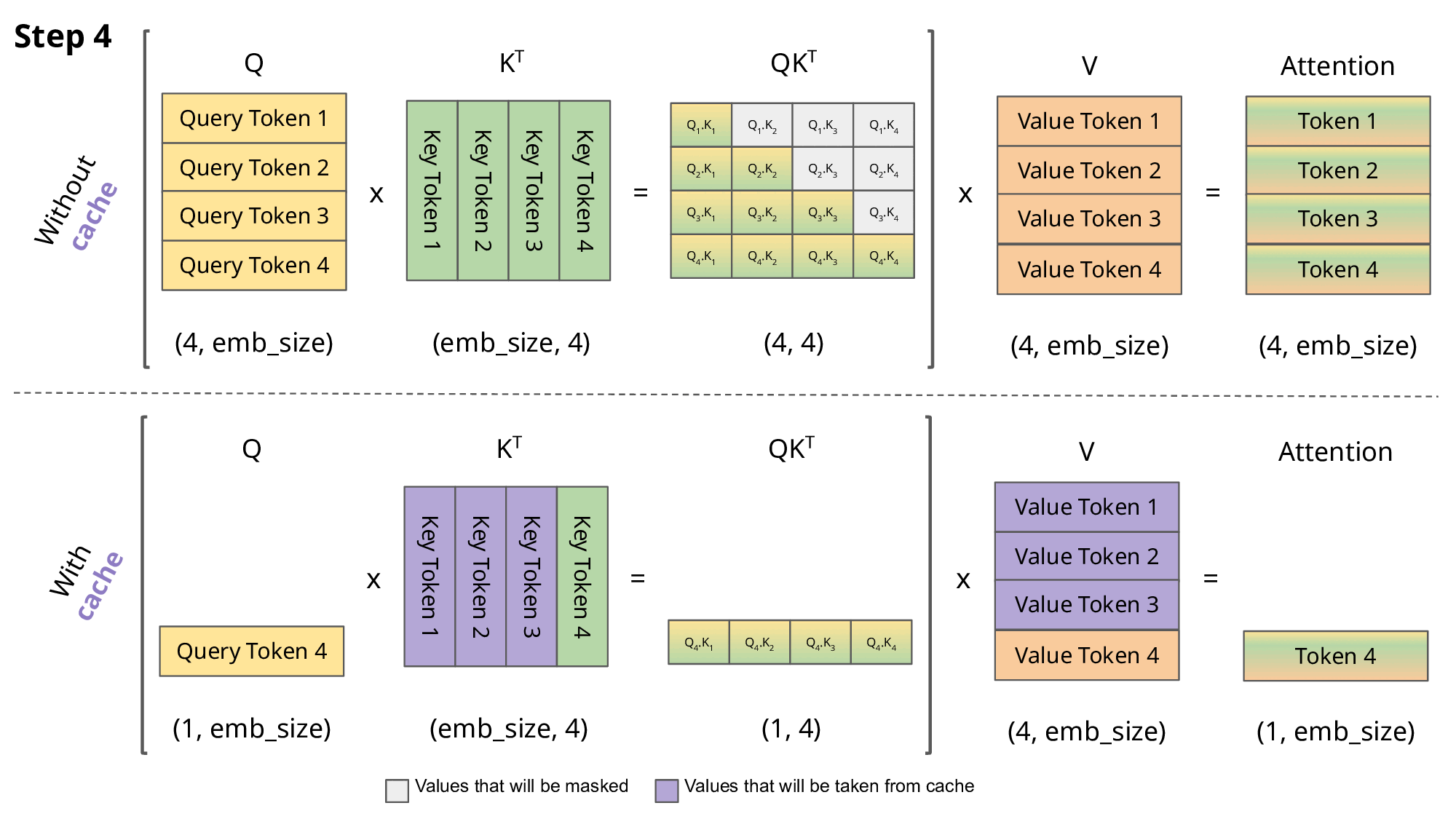
KV cache 이해를 돕기 위한 이미지
KV caching은 계산 리소스를 줄이는 대신 생성된 Key/Value 텐서를 버리지 않고 저장해야 하기 때문에 메모리 사용량이 증가 → 긴 문맥(long-context)을 다룰 때 병목현상이 발생
이러한 문제를 해결하기 위해서, “Multi-Query Attention (MQA), Group-Query Attention (GQA)”와 같이 더 적은 수의 어텐션 헤드를 사용하면 KV cache는 줄일 수 있지만 성능 저하가 발생합니다. DeepSeek-V2는 Multi-head Latent Attention (MLA)라는 혁신적인 주의 메커니즘을 제안하여 훨씬 적은 KV 캐시를 필요로 하면서 높은 성능을 유지합니다.
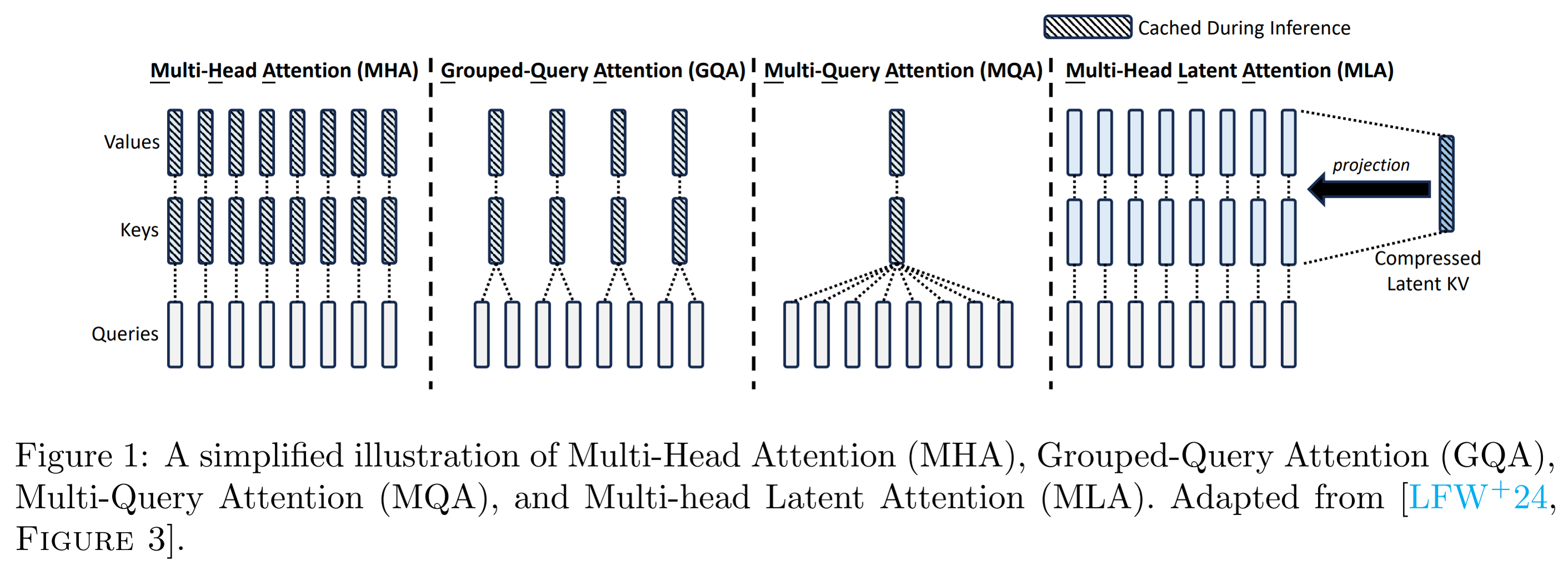
The architecture of MLA
2.1.1 Standard Multi-Head Attention
기존 MHA는 입력 벡터 \(h_t\)로부터 Query, Key, Value를 다음과 같이 별도로 계산합니다:
\[q_t = W^Q h_t,\quad k_t = W^K h_t,\quad v_t = W^V h_t\]각각의 \(q_t, k_t, v_t\)는 \(n_h\)개의 head로 분할되어 attention 연산에 활용되며, 추론 과정에서는 모든 토큰의 Key 및 Value를 캐시에 저장해야 합니다. 이에 따라 토큰당 KV 캐시의 크기는 다음과 같이 정의됩니다:
\[\text{KV Cache per token} = 2 \cdot d_h \cdot n_h \cdot l\]여기서, \(d_h\)는 head 차원, \(n_h\)는 head 수, \(l\)는 레이어 수 입니다.
2.1.2 Low-Rank Key-Value Joint Compression
Multi-Head Latent Attention (MLA)은 Key와 Value를 각각 따로 계산하지 않고, 공통된 저차원 latent vector로 압축하여 표현합니다. 이를 위해 먼저 입력 \(h_t\)를 down-projection하여 latent 표현 \(c_t^{KV}\)를 생성합니다:
\[c_t^{KV} = W^{DKV} h_t\]이후, up-projection을 통해 해당 latent vector로부터 Key와 Value를 복원합니다:
\[k_t^C = W^{UK} c_t^{KV},\quad v_t^C = W^{UV} c_t^{KV}\]Query 역시 동일한 방식으로 압축 및 복원됩니다:
\[c_t^Q = W^{DQ} h_t,\quad q_t^C = W^{UQ} c_t^Q\]이러한 low-rank latent vector 기반 표현은 Key와 Value 정보를 효율적으로 공유하며, 각 토큰에 대해 캐시해야 할 데이터의 크기를 다음과 같이 감소시킵니다:
\[\text{KV Cache per token} = \left( d_c + d_R \right) \cdot l\]DeepSeek-V2에서는 \(d_c = 4d_h\), \(d_R = \frac{1}{2}d_h\)로 설정되므로,
\[\text{KV Cache per token} = \left( 4d_h + \frac{1}{2}d_h \right) \cdot l = \frac{9}{2} \cdot d_h \cdot l\]LLM 구조에서 \(n_h\) 는 일반적으로 8 이상이며 이를 대입하여 계산하였을 때, MLA는 기존 MHA 대비 약 \(3\times\) 이상의 KV 캐시 절감 효과를 달성합니다.
2.1.3 Decoupled Rotary Position Embedding
DeepSeek-V2는 Rotary Position Embedding (RoPE)를 활용합니다. RoPE는 self-attention 식에서 relative position dependency (상대 위치 의존성) 정보를 더하는 방식을 사용합니다. 하지만 MLA 구조에서는 RoPE 연산으로 인해 업프로젝션 행렬 \(W_{UK}\)가 \(W^Q\)에 통합될 수 없어, 추론 시 추가 계산 비용이 발생합니다.
이를 해결하기 위해 DeepSeek-V2는 RoPE를 decoupled하여, Query와 Key에 별도의 구조를 적용합니다. 자세한 식은 원 논문에서 한번 읽어보시는 것을 권장합니다.
따라서, MLA는 기존의 full-rank attention보다 저차원 구조를 사용함에도 불구하고, 더 나은 성능을 입증하였습니다. 이를 저자들은 Decoupled RoPE의 도입으로 인한 효과일 것이라고 분석하였으나, 해당 기법의 정확한 효과를 정량적으로 분석한 Ablation Study가 존재하지 않기 때문에, 후속 연구에서 다뤄야 할 중요한 주제라고 강조합니다.
2.2 Mixture of Experts
Mixture of Experts (MoE)는 모델의 파라미터 수를 늘리면서도 계산량은 상대적으로 적게 유지하기 위한 구조로, Transformer의 Feed-Forward Network(FFN) 대신 여러 개의 전문가 네트워크(Expert)를 선택적으로 활성화하는 방식입니다. DeepSeekMoE는 기존 MoE 아키텍처를 기반으로 다음과 같은 주요 개선 사항을 도입하였습니다.
2.2.1 Fine-Grained Expert Segmentation
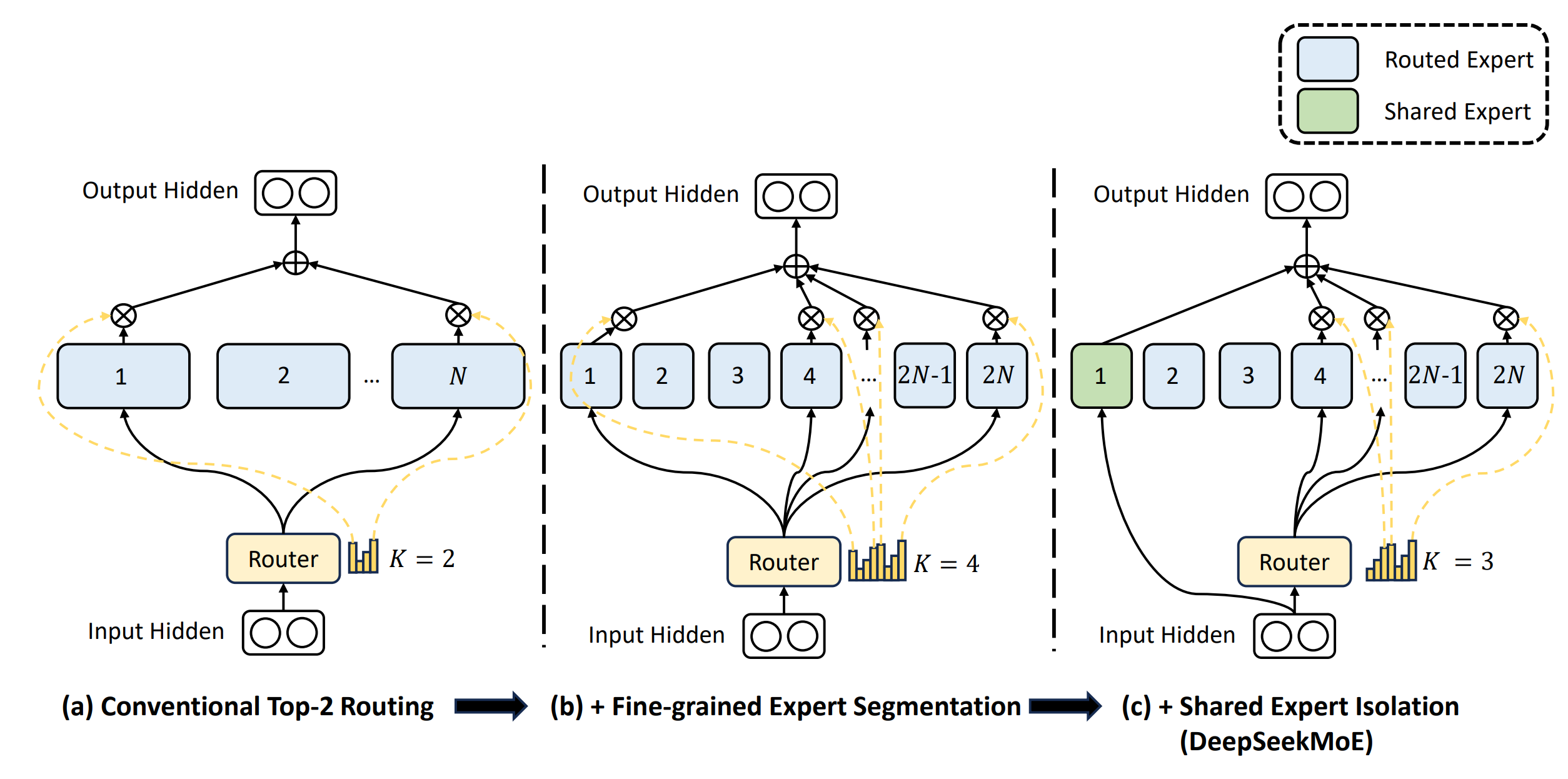
An illustration of DeepSeekMoE
기존 MoE에서는 하나의 FFN 블록을 하나의 Expert로 사용했다면, DeepSeek에서는 이를 여러 개의 작은 세그먼트로 나누어 더 세분화된 Expert 구조를 구성합니다 (그림 (b) 참고). 이러한 fine-grained segmentation strategy는 전문가의 조합적 유연성을 크게 향상시켜, 모델의 더 세밀한 학습 향상을 달성한다고 하였습니다.
2.2.2 Shared Expert Isolation
또한 DeepSeekMoE는 Shared Expert 개념을 도입하여, 다양한 맥락에서 발생하는 공통된 지식을 모든 토큰에 전달함으로써 표현의 일관성과 파라미터 공유를 극대화하였습니다.
모든 토큰은 고정된 일부 Shared Expert를 항상 사용하며, 나머지는 입력에 따라 선택적으로 활성화되는 Routed Expert로 구성됩니다 (그림 (c) 참고). 이를 통해 공통 지식과 특화된 지식의 분리를 명확히 하고, 각 Expert 간 파라미터 중복을 줄여 계산량이 크게 감소합니다.
2.2.3 Load Balancing
MoE 구조에서 흔히 발생하는 문제 중 하나는 특정 Expert에만 토큰이 과도하게 몰리는 현상입니다. 이는 일부 Expert는 과적합되고, 나머지는 학습이 덜 되는 문제를 야기합니다.
DeepSeek는 다음과 같은 방식을 통해 이를 완화합니다:
- Expert-level Load Balancing Loss: 모든 Expert가 균등하게 선택되도록 유도하는 보조 손실 항을 추가
- Auxiliary-loss-free load balancing: 각 Expert의 선택 확률에 따라 동적으로 bias term을 조정하여, 과도하게 선택되거나 선택되지 않은 Expert의 활성화를 조절(bias는 Top-K routing 결정에만 사용)
- Sequence-level Auxiliary Loss: DeepSeek-V3에서는 시퀀스 단위 보조 손실함수를 적용하여 특정 시퀀스 내에서도 Expert가 편향되지 않도록 조정
2.3 Multi-Token Prediction
기존의 언어 모델은 일반적으로 한 번에 하나의 토큰을 예측하는 next-token prediction 방식을 따릅니다. 이에 반해 DeepSeek-V3는 학습 효율을 높이기 위해 Multi-Token Prediction (MTP) 기법을 도입하였습니다. 이 방법은 각 입력 토큰에 대해 단일 토큰이 아닌 여러개의 토큰을 예측하도록 설계되어, 더 많은 학습 신호를 제공하고 sample efficiency를 크게 개선합니다.
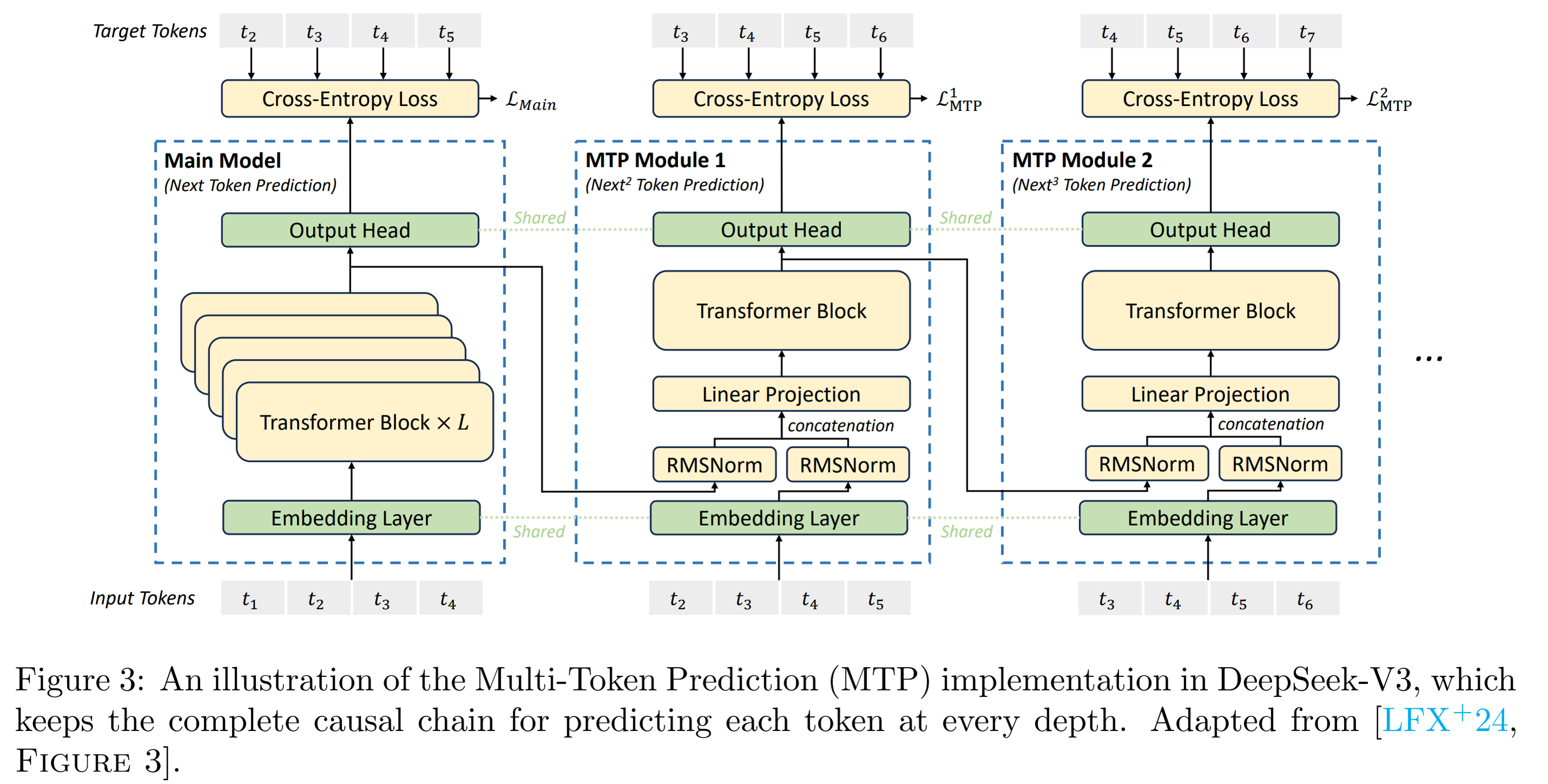
An illustration of the Multi-Token Prediction (MTP) implementation in DeepSeek-V3
MTP의 주요 이점은 sample efficiency를 향상시키고, 모델 성능을 높일 수 있다는 점입니다. 그러나, MTP 모듈의 계층적 구조로 인해 기존 next-token prediction 방식보다 training overhead가 증가하며, 이러한 추가적인 ablation study이 필요하다고 저자는 강조합니다.
2.4 Co-design of Algorithms, Frameworks and Hardware
DeepSeek-V3는 모델, 알고리즘, 프레임워크, 하드웨어 전반에 걸친 co-design을 통해 학습 효율을 극대화하였습니다. 특히 14조 8천억 개의 토큰에 대한 모델의 사전 학습을 약 278만 8천 H800 GPU 시간 시간 내에 완료할 수 있었던 주요 요인 중 하나입니다.

An illustration of the DualPipe scheduling algorithm
DualPipe는 DeepSeek에서 도입한 새로운 형태의 pipeline parallelism 기법으로, 개별적인 한 쌍의 forward와 backward chunk 내에서 계산과 통신을 겹치게 수행함으로써, communication overhead를 효과적으로 줄였습니다. 이 알고리즘은 각 chunk를 네 부분으로 나누고, backward 단계를 다시 input과 weight 계산으로 분리하여 pipeline bubble을 최소화합니다.
특히 위의 그림과 같이 bidirectional 방식의 스케줄링을 사용하여 양쪽 끝에서 동시에 데이터를 공급하는 구조로 설계되었으며, 이로 인해 all-to-all communication 비용을 거의 0에 가깝게 감소시킬 수 있습니다.
그러나, 이 구조는 모델 파라미터를 두 배로 유지해야 하므로 메모리 사용량이 증가하며, 최근 연구에서는 해당 구조를 단순화한 방식(“cut-inhalf” 라고 함)도 제안되고 있습니다.
또한, DeepSeek는 학습 속도를 더욱 향상시키기 위해 FP8 mixed precision training을 도입하였습니다.
주요 연산 커널(GEMM 등)을 FP8 형식으로 수행하여 속도를 높이는 한편, embedding, attention, normalization과 같은 중요한 연산은 유지함으로써 정확도와 수치 안정성 간의 균형을 확보하였습니다.
저자들은 이러한 알고리즘-프레임워크-하드웨어의 통합적 최적화 전략은 DeepSeek의 대규모 pretraining을 가능하게 만든 핵심 설계 요소 중 하나라고 언급하였습니다.
2.5 Group Relative Policy Optimization
Group Relative Policy Optimization (GRPO)는 DeepSeek에서 기존의 Proximal Policy Optimization (PPO)을 대체하기 위해 도입된 효율적인 강화학습 기법입니다.
LLM에서 reward는 일반적으로 출력의 마지막 토큰에만 할당되며, 이는 value function 학습을 어렵게 만드는 요인입니다. 또한 PPO는 reward를 기반으로 각 단계의 advantage를 계산하기 위해 별도의 value network를 필요로 하며, 이는 모델 크기 및 메모리 부담을 증가시킵니다.
이를 해결하기 위해 GRPO는 value model 없이 직접 advantage를 추정하여 메모리 사용량을 크게 줄입니다.
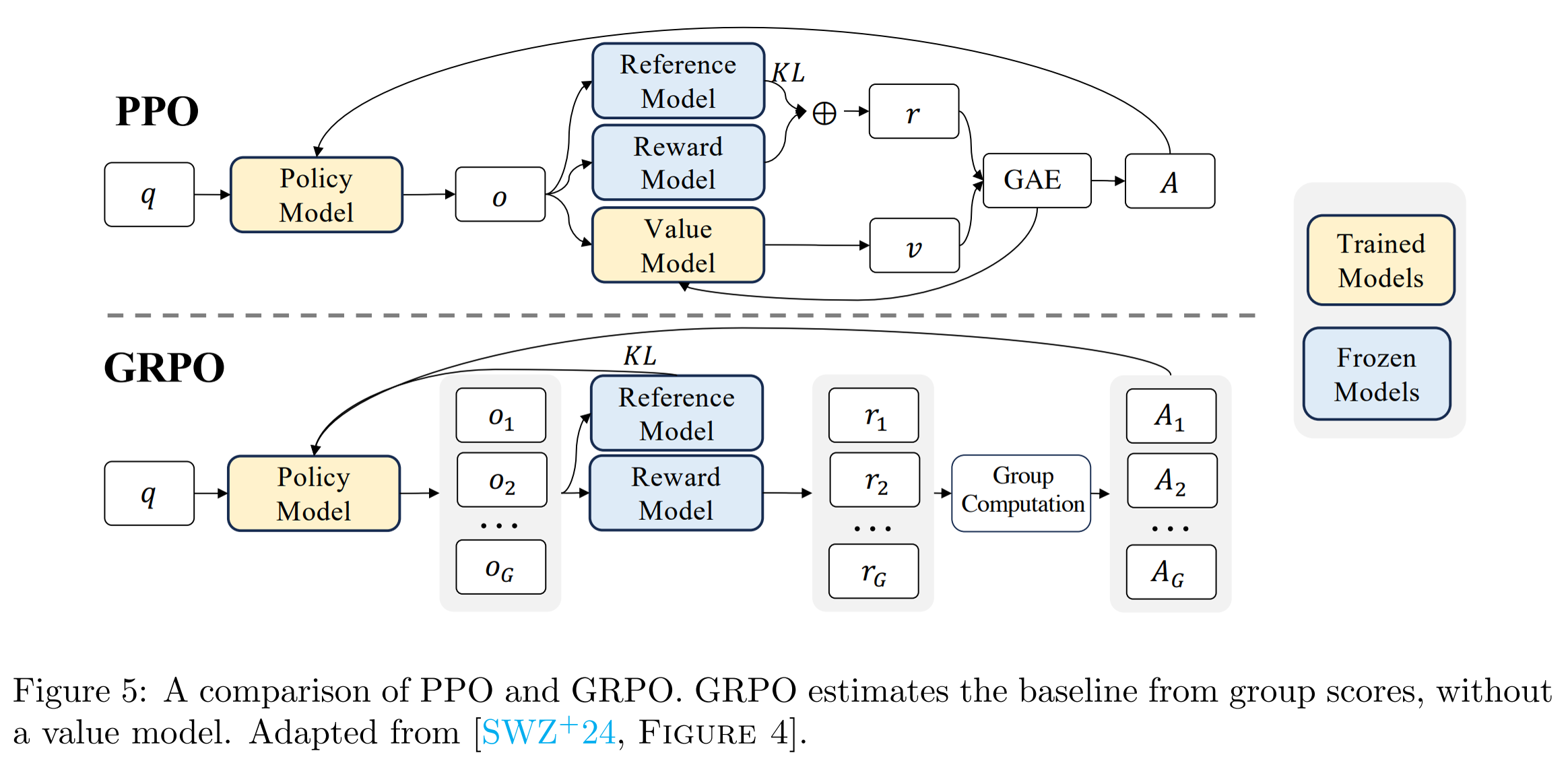
Comparison between PPO and GRPO in DeepSeek
먼저 GRPO는 기존 policy로부터 여러 개의 output 후보들을 생성하고, reward model로부터 각 후보에 대한 점수를 얻습니다. 이후 그룹 내 상대적인 reward를 기반으로 advantage를 직접 계산합니다.
- Outcome supervision: 전체 출력에 대해 하나의 reward를 부여하고, 이를 모든 토큰에 동일하게 적용
- Process supervision: 출력 과정의 각 단계마다 reward를 부여하고, 후속 reward를 누적하여 각 토큰의 advantage로 계산
이 방식은 value function 학습 없이도 정책의 개선 방향을 정교하게 추정할 수 있도록 합니다.
따라서, GRPO는 PPO와 유사한 성능을 유지하면서도 훨씬 낮은 GPU memory 사용량을 제공하기 때문에, 대규모 모델 학습에 매우 적합합니다.
2.6 Post-Training: Reinforcement Learning on the Base Model
DeepSeek-R1 시리즈는 pretraining이 완료된 base 모델(DeepSeek-V3-Base)을 기반으로, 강화학습 (RL)을 적용하여 모델의 reasoning 능력과 응답 품질을 고도화합니다. 특히 DeepSeek-R1-Zero는 supervised fine-tuning (SFT) 없이, 순수 RL만으로 성능을 끌어올린 사례로 주목받고 있습니다.
DeepSeek-R1-Zero는 SFT 데이터를 사용하지 않고, base 모델에 pure RL을 적용하여 학습됩니다.
이 과정에서는 GRPO 알고리즘이 사용되며, 다음과 같은 reward signal이 적용됩니다:
- Accuracy reward: 정답 유무에 따른 평가 점수
- Format reward: 모델이
<think>...</think>태그 내에 사고 과정을 구조화하여 표현하도록 유도
이러한 reward 기반 학습을 통해 모델은 별도의 지시 없이도 자연스럽게 reasoning과 alternative solution exploration 능력을 습득합니다.
그러나, 순수 RL 기반 학습은 일부 부자연스러운 문장 구성이나 언어 혼용 현상(language mixing)과 같은 문제가 나타날 수 있습니다.
DeepSeek-R1은 이러한 문제를 해결하고 성능을 더욱 고도화하기 위해, SFT와 RL을 결합한 multi-stage training pipeline을 구성합니다.
총 4단계로 진행됩니다:
- Cold Start
- 수천 개의 long-form Chain-of-Thought(CoT) 샘플로 base 모델을 SFT하여, 안정적인 RL 시작점을 확보합니다.
- Reasoning-oriented RL
- GRPO 기반 강화학습 수행
- 언어 일관성을 높이기 위한 language consistency reward 도입
- Rejection Sampling + SFT
- RL 단계에서 생성된 응답 중 올바른 샘플만 선별(600K)하여 SFT
- 추가적으로 약 200K의 일반 SFT 데이터도 포함하여 모델의 표현력 보완
- RL Alignment
- 최종적으로 모델이 helpfulness와 harmlessness 기준을 만족하도록 미세 조정
- 응답의 유용성과 안전성을 모두 고려하여 정렬(Alignment) 수행
이러한 iterative training 전략은 단순한 성능 개선을 넘어, 모델이 합리적 사고를 통해 문제를 해결하고, 사람의 답변과 같은 응답을 생성할 수 있도록 만듭니다.
논문 리뷰 총평
해당 논문 리뷰를 통해 DeepSeek가 단순히 높은 성능의 언어 모델을 개발하는 데 그치지 않고, 이를 실제로 구현 가능하고 효율적으로 동작하는 수준까지 어떻게 정교하게 최적화했는지를 알아볼 수 있는 계기가 되었습니다.
Multi-Head Latent Attention, Mixture of Experts, Multi-Token Prediction, GRPO 등 최신 LLM 논문에 자주 나오는 구성 요소들에 대해 더 깊이 있게 공부해야겠다는 생각이 들었고, 앞으로의 연구나 개발 과정에서도 성능에만 집중하기보다는 실제 환경에서 적용 가능한 수준의 최적화까지 함께 고려하는 시각이 필요하다는 점을 다시금 느꼈습니다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: